

Robots.txt is a simple and short text file stored in the root directory of a domain that instructs search engine crawlers like Googlebot, what they are allowed to crawl on your site.
In SEO, robots.txt helps crawl the pages of high importance first, preventing them from visiting the ‘second-hand’ pages. To accomplish that, robots.txt excludes entire domains, one or more subdirectories or individual files, and even complete directories from search engine crawling.
However, this simple text file doesn’t controls crawling and integrates a link to your Sitemap. This gives website crawlers an overall view of the current URLs that exist in your domain.
That’s what a robots.txt file looks like:
As we mentioned a little earlier, you can find robots.txt at any domain homepage by simply adding “/robots.txt” at the end.
Here is an example of an actual, working robots.txt file:
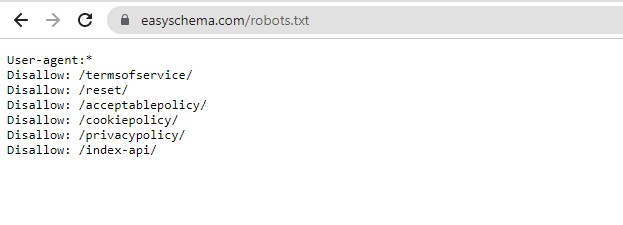
https://yourdomain.com/robots.txtDon’t forget that the robots.txt file is a public folder that you can find on nearly every website, such as Facebook, Apple, and even Amazon. Robots.txt is the first document that search engine crawlers open when visiting your website. You should also know that robots.txt is weak in protection against unauthorized access.
Why is a robots.txt file important?
The fundamental purpose of the robots.txt file is to show website crawlers the area on your website they have access to and show them how they should interact with all pages. Search engines have to find your web pages before they end up in search results; that’s why your website’s content needs to be crawled and indexed first.
But in some cases, it’s better to ban crawlers from visiting specific pages such as empty pages, login pages (for your website), and so on. That’s why we need to use a robots.txt file, as it is always checked by web crawlers right before they start crawling the website as a whole.
Another thing to consider is that robots.txt is only used to prevent search engines from crawling, not indexing.
Even though website crawlers might not have access to a particular page, search engines may continue to index it if external links are directed.
Besides this primary purpose of the robots.txt file, many other SEO benefits can be beneficial in different situations.
First, they can optimize the crawl budget.
The crawl budget indicates the total number of pages that website crawlers (e.g., Googlebot) will crawl within a specific amount of time.
Some larger websites contain dozens of unimportant pages that do not need to be indexed or crawled, and robots.txt tells search engines the exact pages to crawl. So, using the robots.txt file optimizes the crawling frequency and efficiently helps page indexes.
Second. They can manage duplicate content.
Robots.txt can prevent the crawling of similar or duplicate content on your web pages. As you now know, there are a lot of websites that contain forms of the same content. These pages can be www vs. non-www pages, URL parameters (HTTP encryption) and identical PDF files, etc.
You can avoid crawling these pages by using the robots.txt file to point them out. So, by using robots.txt, you can manage content that is unnecessary to be crawled, helping the search engine crawl only pages you want to appear in SERPs.
Third. They can prevent servers from overloading.
Using the robots.txt file can prevent your website server from crashing. Website crawlers such as Googlebot are known for their ability to determine how fast your website should crawl, regardless of your website server capacity. However, sometimes you can get bothered by how often specific web crawlers visit your site, and you may probably want to block them. The urge to block some bots comes when a lousy bot overloads your website with requests or when block scrapers try to copy all your site’s content, which can cause a lot of site issues.
It is essential to use robots.txt because it tells web crawlers the specific pages to turn their focus. In this way, the other pages of your website will be left alone, which will prevent the site from overloading.
How does a robots.txt file work?
The fundamental principles that indicate how a robots.txt file works consist of 2 essential elements. Both elements are related tight to each other, and they dictate a specific website crawler to do something (user-agents) and what they should do (directives).
User agents specify which will direct web crawlers to crawl or avoid crawling certain pages, whereas directives indicate user agents should do with these pages.
This is what they look like:
User-agent: Googlebot
Disallow: /wp-admin/Down below, you have an in-depth survey on these two elements.
- User-agents
User-agent represents a specific crawler instructed by directives on crawling your site.
e.g., the user-agent for the Google crawler is “Googlebot,” for Yahoo is “Slurp,” for Bing crawler is “BingBot,” etc.
In case you want to mark all types of bots for a particular directive at once, use the wildcard symbol, “*.” This symbol represents all types of website crawlers that have to follow the directives’ rules.
This is what this symbol looks like in the robots.txt file:
User-agent: *
Disallow: /wp-admin/You have to keep in mind that several user agents are focused on crawling for their purposes.
- Directives
Whereas robots.txt directives are the instructions that specified user-agents have to follow. Directives instruct web crawlers to crawl every available page, and then it’s time for the robots.txt file to decide which pages shouldn’t crawl pages (or sections) on your website.
Here are three standard rules used by robots.txt directives:
- “Disallow” –tells web crawlers not to access anything specified within this directive. You can designate several disallow instructions to user agents.
- “Allow” – tells web crawlers that they can now access some pages from the current disallowed website section.
- “Sitemap” – if you already arranged an XML sitemap, robots.txt tells crawlers where they can find web pages that you want to be crawled (pointing crawlers to your site map).
Here is an example of these three directives for wordpress sites:
User-agent: Googlebot – the specific crawler
Disallow: /wp-admin/ – the directive (tells Googlebot that we do not want access to the login page for a WordPress site).
Allow: /wp-admin/random-content.php – we added an exception – Googlebot can visit that specific address (it cannot access anything else under the /wp-admin/folder).
Sitemap: https://www.example.com/sitemap.xml – a list of URLs that you want to be crawled – we instructed Googlebot where to find your Sitemap.
Here are a few other rules that can apply to your robots.txt file if your site contains dozens of pages that need to be managed somehow.
- * (Wildcard)
This directive indicated a rule for matching patterns, and it is used mainly for websites that contain filtered product pages, dozens of generated contents, etc.
For instance, instead of disallowing each product page under the /products/ section one-by-one as in the example below,
User-agent: *
Disallow: /products/shoes?
Disallow: /products/boots?
Disallow: /products/sneakers?you can use the wildcard directive to disallow them all at once:
User-agent: *
Disallow: /products/*?
$This symbol is used to define the end of a URL.
May instruct web crawlers whether they should crawl URLs with an ending.
Example:
User-agent: *
Disallow: /*.gif$
In this example, the "$" sign indicates crawlers to ignore all URLs that end with ".gif."
#This sign serves in the same way that comments/annotations help human readers. The “#” symbol doesn’t indicate a directive and has no impact on user agents.
# We don’t want any crawler to visit our login page!
User-agent: *
Disallow: /wp-admin/
How to compose your own robots.txt file?
If you use WordPress for your website, you will have a default robots.txt file there. Anyway, a few plugins like Yoast SEO, Rank Math SEO, or All in One SEO can help you manage your robots.txt file in case you want to make some changes in the future.
These plugins can help you easily control what you want to allow or disallow, so you don’t have to write any complicated syntax all by yourself.
Robots.txt file best practices.
You have to know that robots.txt files can quickly get complex, so it’s better to keep things under control – as simple as possible.
Down below, you have some tips on how to create and update your robots.txt file:
- Use separate files for subdomains – if your site has multiple subdomains, the best you can do is treat them as different websites. You have to create separated robots.txt files for every subdomain you own.
- Ensure specificity –you have to specify the exact URL paths, and you also have to pay attention to specific signs (or any trailing slashes) that are present or missing on your URLs.
- Specify user-agents just once – merge all directives of a specific user-agent. This helps you establish simplicity and organization in your robots.txt file.


