

A canonical tag, often called rel=canonical, is part of HTML code that helps SEO identify the main version from similar or other identical pages. In SEO, canonical tags serve as means of identification for Google. Google knows exactly which version of the page you want to display in SERPs through them. In addition, this markup is used to point out the original content source from the duplicate content pages and improve the crawling, indexing, and your website’s performance in general.
Here is an example of how a canonical tag looks like:
<link rel="canonical" href="https://easyschema.com/robots-txt/" />The importance of canonical tags in SEO:
As we mentioned above, the main goal of canonical tags is to let search engines quickly notice the original page and the duplicated one. Duplicates are pages from the main webpage with different URLs that display the same content. Then, Google has to pick the right page for indexing and ranking purposes. It won’t use all the pages as search results because they all look similar.
An excellent example of that is the product pages commonly displayed by more than 1 (primary) URL. They are shown with several URL parameters that can be used for sorting, sizes, currency, etc., for example:
- https://www.randomshop.com/clothes/shirts.html
- https://www.randomshop.com/clothes/shirts.html?Size=XL
- https://www.randomshop.com/clothes/shirts.html?Size=XL&color=red
As you can see in the example, a product page is displayed in the main category (clothes) and with various URL parameters such as size and color. Again, canonical tags play an excellent role in this, indicating to Google that the main URL category/clothes are the one that needs to be indexed and used as a search result.
Underline that Google does not perceive the canonical tag as a directive but as a signal (which sometimes may be ignored).
Here are some essential SEO benefits that come with canonical tags:
They help to consolidate link equity (PageRank)
As you now know, canonical tags can help consolidate PageRank from all duplicate pages displayed on the main page. Duplicate pages usually contain backlinks from external resources such as backlinks from random sites, users on social media, and so on.
Setting up canonical tags on these duplicate pages, PageRank turns into a single URL, which will help you improve the overall ranking in Google Search.
They can help manage syndicated content.
Canonical tags let Google know the website that contains the original version of content and the one that just republished it. Many site owners often use other sites to publish their content for promotional or informative purposes when Google must make the right decision on the website with the original content and display it in Google Search.
Implementing canonical tags on duplicated websites (they promote the original content) can help you solve the problem and display the original version as a search result.
They can improve crawling.
You can help Google or other search engines crawl the page you want to index more efficiently. In contrast, duplicate pages shouldn’t be crawled at all. Despite being irrelevant for crawling and indexing purposes, pages containing identical content also waste a lot of Google’s time and resources.
With canonical pages, Google can be more focused on pages that matter, and in this way, it can save that what is called “crawl budget.”
How to add a canonical tag to your pages?
Adding a canonical tag to your webpage is pretty simple. But, first, you must add a rel-“canonical” tag into every duplicate web page in the <head> section.
Note: The link in the canonical tag you are adding must denote the main version of the webpage.
Implementing a canonical tag on a page-by-page basis may take you a lot of time and consume many resources. Not only that but adding these canonical tags on large web pages can be almost impossible.
But here is an optimal solution for that.
You can automatically implement a canonical tag via distinct plugins like Yoast SEO that can be used for WordPress. Implementing the canonical tags using this plugin (Yoast SEO) can be applied genuinely.
First, choose the page you want to add the canonical tag.
Second. Go to the “Advanced” section of this page.
Third. Then implement the canonical URL that you wanted to refer to at first.
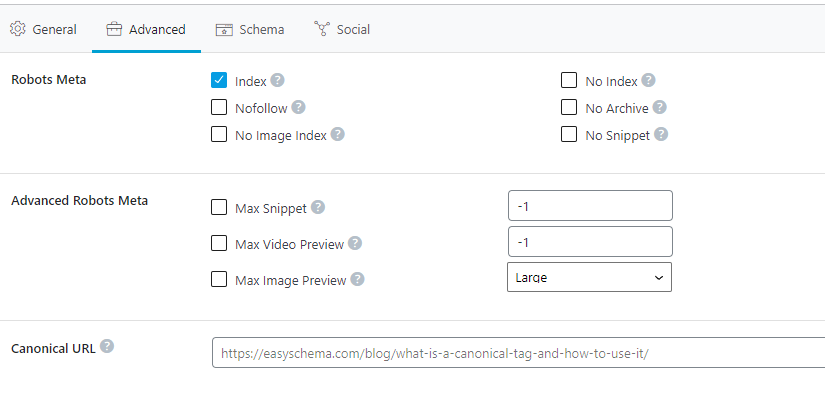
We will also show you some other methods that you can use to indicate to a search engine your canonical web pages.
Use HTTP header.
Another good way to implement a canonical tag is by adding it in the HTTP header of the page. This method is mainly used for specific non-HTML documents (PDFs) that do not contain the <head> section to add a canonical tag as usual. When adding canonical tags to the HTTP header, you have to initially ask for access in the .htaccess file of your website. Once you have done that, you can continue adding the canonical tag that will appeal in this form:
Link: <https://www.yoursite.com/random-document.pdf>; rel=”canonical”
Down below, you will find a few other methods on how you can let Google know about the pages you want to be main, canonical versions.
- Sitemap – There is not much to guess for Google that the URLs listed in Sitemap are the main canonical versions
- Internal linking – Your website contains internal links that can help Google decide easily whether a page is canonical or not by directing them to duplicate pages.
- Redirect – Pages with duplicate content can transfer traffic and page signals into the canonical URL using 301 directs.
- HTTPS –Many search engines, including Google, prefer canonical pages, as they provide a valid SSL certificate (the HTTP encryption).
The best canonical tag practices
- Self-referencing canonicals
It is always an excellent strategy to implement a canonical tag on a webpage that points to itself. Once you use self-referencing rel=canonical on the original ou webpage, Google can see clearly that it is a canonical version.
- Absolute URLs usage
Using absolute URLs in canonical tags can prevent unintentional mistakes and avoid bad interpretations of canonical URLs by Google. Know that absolute URLs have to include hhtps, //, www, as well as trailing slashes when possible. Here is what an absolute URL looks like in a canonical tag,
<link rel="canonical" href="https://www.randomwebsite.com/randompage/" />and here is what a relative URL looks like:
<link rel="canonical" href="/randompage/" />- Use lowercase URLs
You should know that the upper and lower cases in the URLs considerably impact Google and other search engines. Therefore, you can avoid duplication issues by using lower chances in canonical URLs.
- Canonicalize cross-domain duplicates
Canonical tags can also be used to an instance of
your main page from other domains (not only from your site). There are two things that you can do if you have duplicate content on several pages of a different website:
- Use self-referencing canonical tag on your webpage
- Apply the canonical tag on the external website (referencing your original page)
What to avoid when using canonical tags?
Multiple canonicals on a single page.
Although it happens rarely, several canonical tags may occur in the HTML of a page against your will. Anyway, you have to pay attention to this inconvenience because it can cause massive confusion for Google (and any other search engines), ignoring the canonical signal.
Avoid canonicals on non-duplicate pages.
When implementing canonical tags, you have to make sure that the content on the duplicate pages is very similar (or better identical) to the primary, original version of the page. Applying canonical tags on totally different pages is pointless, and it can confuse search engines or be negligible.
Canonical tags on paginated pages.
Pagination is a procedure of dividing web content into different pages. First, you must understand that pagination pages consist of offragmentedcontent divided into other pages. For example, the comment section on a website is divided into several pages “1”, “2”, “3”.
In this case, you have to use self-referencing tags on each of these individual pages and not refer only to page “1”.
Don’t block canonical tag URLs by robots.txt
Keep in mind that you should never block canonicals vis robots.txt files. That’s because these types of files (robots.txt) prevent search engines from crawling duplicate pages. In this way, Google or other search engines can’t see canonical tags reference the original version of the page.
Plus, blocking canonicals via robots.txt files would prevent the transfer of PageRank into your main versions.
Don’t use canonical in the <body> section
You should know that canonical tags are only applied in the <head> section of the page in the HTML document. So, if you implemented a canonical tag in the <body> section (or any other place), the search engine would ignore it.
Avoid canonical loops & chains.
You have to be careful and avoid canonical loops by always using canonical tags that can refer directly to your original page version. E.g., suppose you first use canonical tags from page X to page Y and later use them from page Y to page Z. In that case, you will create a canonical chain, which will confuse Google (or other search engines) and make them waste their time and resources.


